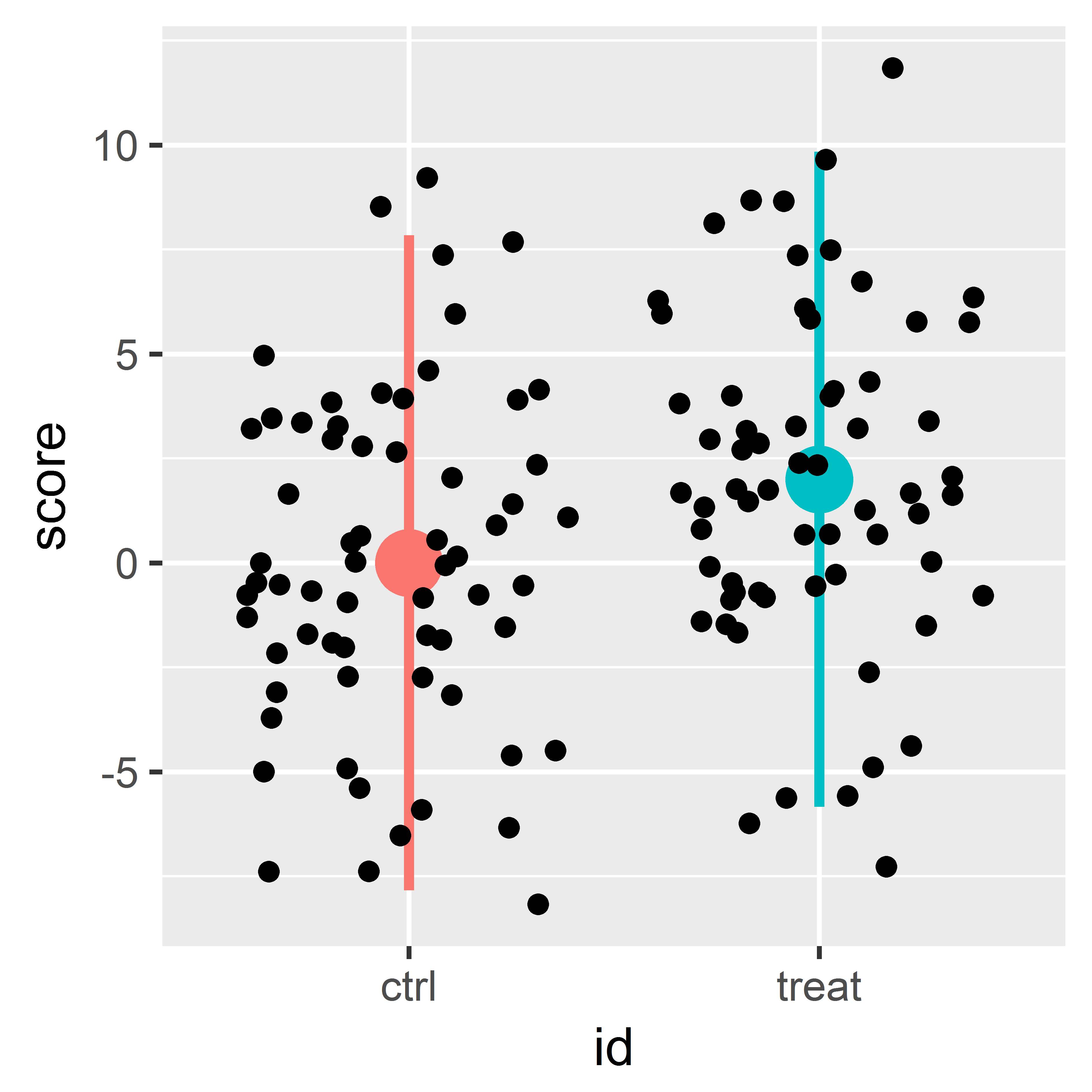
Reference example
- Reference example used throughout the workshop !!
Apriori specifications
- intend to perform a statistical test
- comparing 2 equally sized groups
- to detect difference of at least 2
- assuming an uncertainty of 4 SD on each mean
- which results in an effect size of .5
- evaluated on a Student t-distribution
- allowing for a type I error prob. of .05 (α)
- allowing for a type II error prob. of .2 (β)
Sample size
conditional on specifications being true
Formula you could use
For this particular case:
- sample size (n →
?) - difference ( Δ =signal →
2) - uncertainty ( σ =noise →
4) - type I errors ( α →
.05, so Zα/2 → -1.96) - type II errors ( β →
.2, so Zβ → -0.84)
- sample size (n →
Sample size = 2 groups x 63 observations = 126
Note: formula's are test and statistic specific
logic remains sameThis and other formula's implemented in various tools
our focus:GPower
n=(Zα/2+Zβ)2∗2∗σ2Δ2
n=(−1.96−0.84)2∗2∗4222=62.79
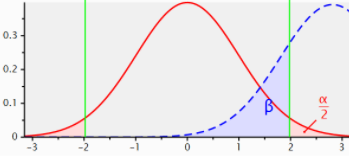
GPower: the building blocks in action
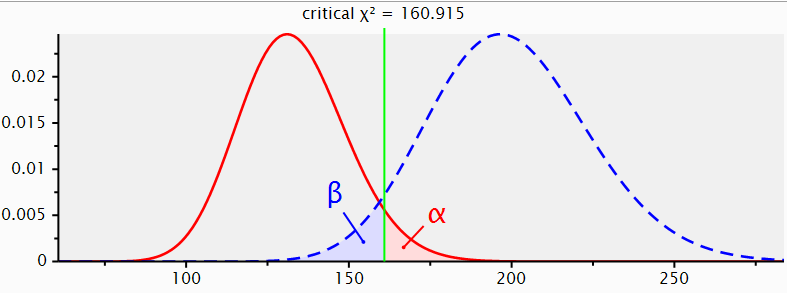
4 components and 2 distributions
- distributions: Ho & Ha ~ test dependent shape
- SIZES: effect size & sample size ~ shift Ha
- ERRORS :
- Type I error ( α ) defined on distribution Ho
- Type II error ( β ) evaluated on distribution Ha
Calculate sample size based on effect size, and type I / II error

GPower: a useful tool
Use it
- implements wide variety of tests
- free @ http://www.gpower.hhu.de/
- popular and well established
- implements various visualizations
- documented fairly well
Maybe not use it
- not all tests are included !
- not without flaws !
- other tools exist (some paying)
- for complex models: impossible
alternative: simulation (generate and analyze)
GPower statistical tests
- Test family - statistical tests [in window]
- Exact Tests (8)
- t-tests (11) →
reference - z-tests (2)
- χ2-tests (7)
- F-tests (16)
- Focus on the density functions
- Tests [in menu]
- correlation & regression (15)
- means (19) →
reference - proportions (8)
- variances (2)
- Focus on the type of parameters
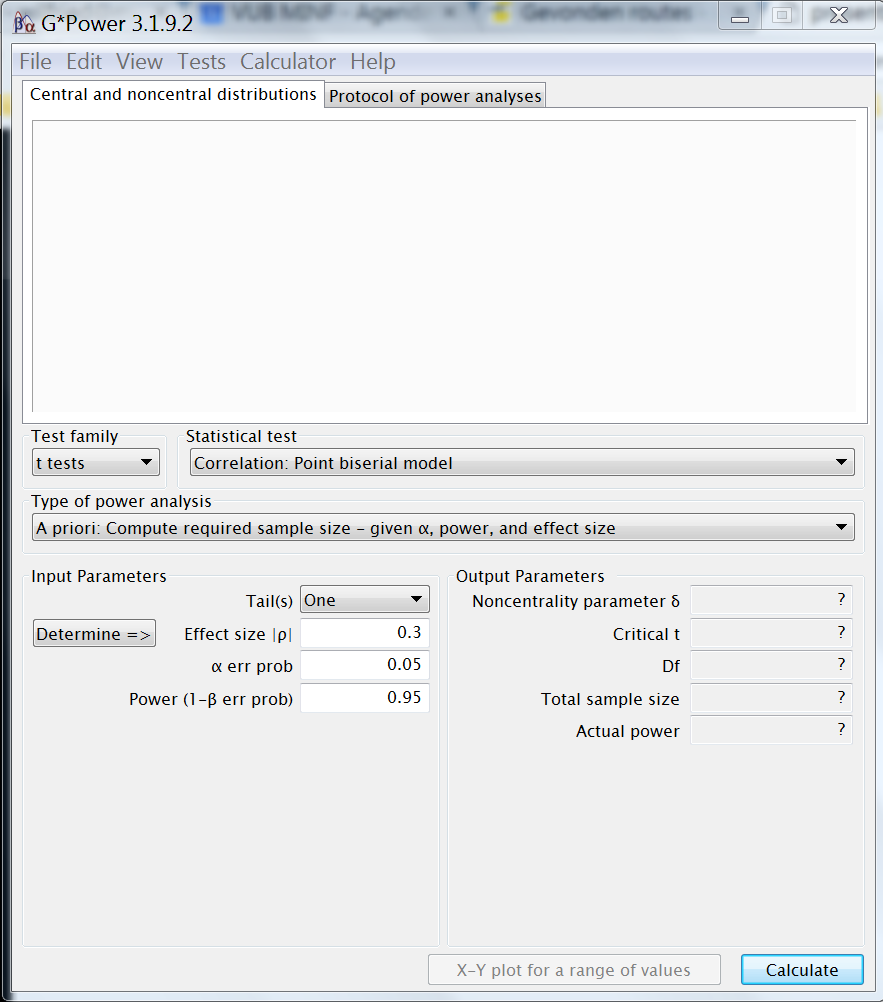
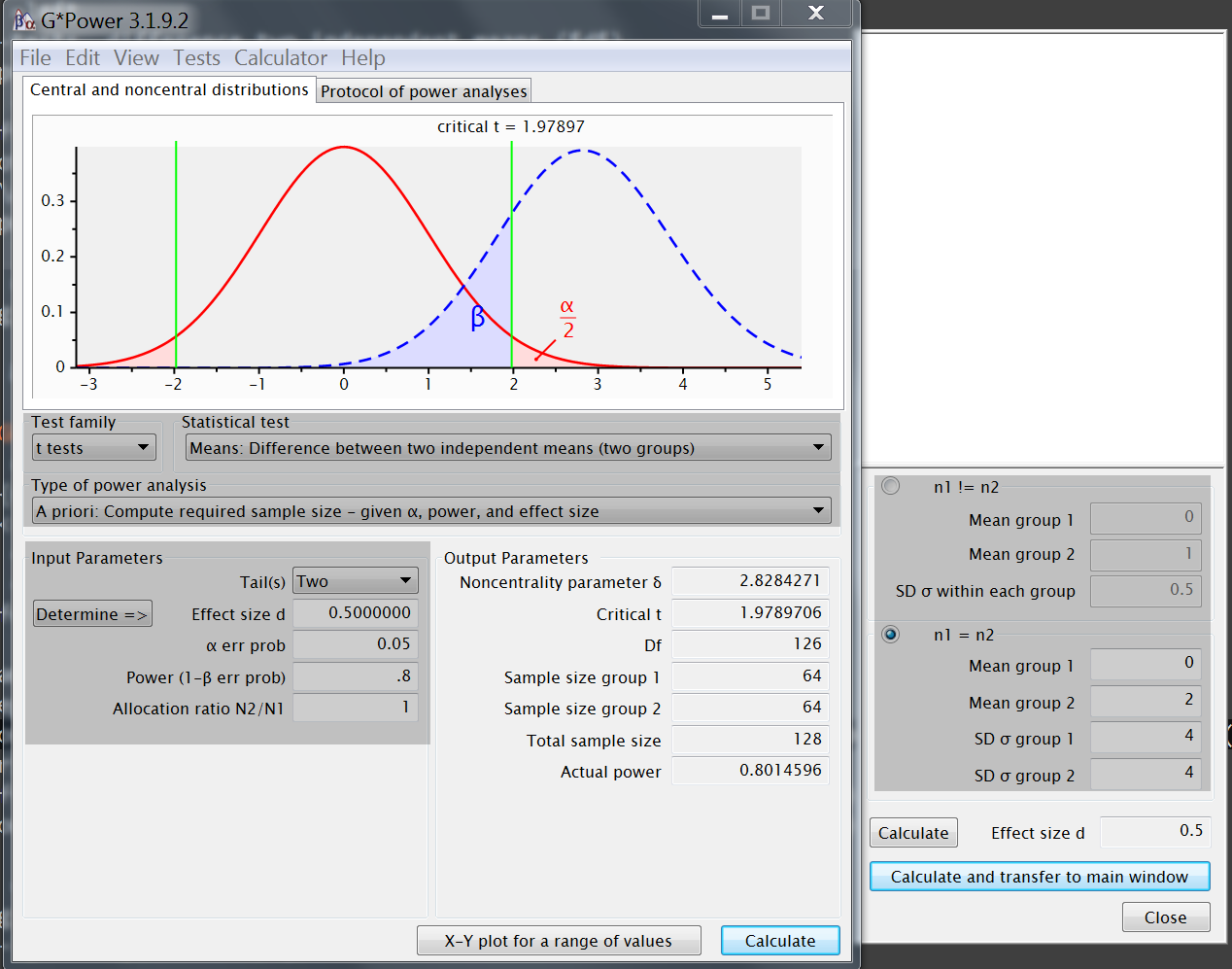
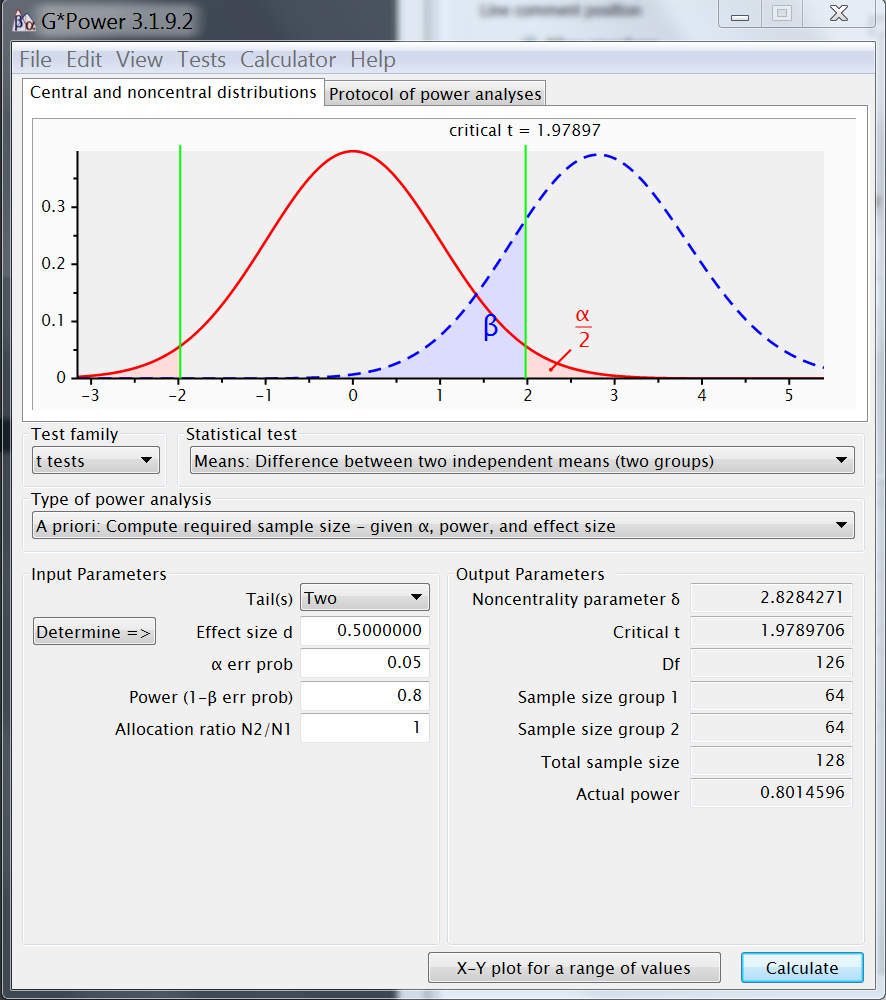
GPower input
~ reference example input- t-test : difference two indep. means
- apriori: calculate sample size
- effect size = standardized difference
- Cohen's d
- Determine =>
- d = |difference| / SD_pooled
- d = |
0-2| /4=.5
- α =
.05
2 - tailed( α /2 → .025 & .975 ) - power=1−β =
.8 - allocation ratio N2/N1 =
1
(equally sized groups)
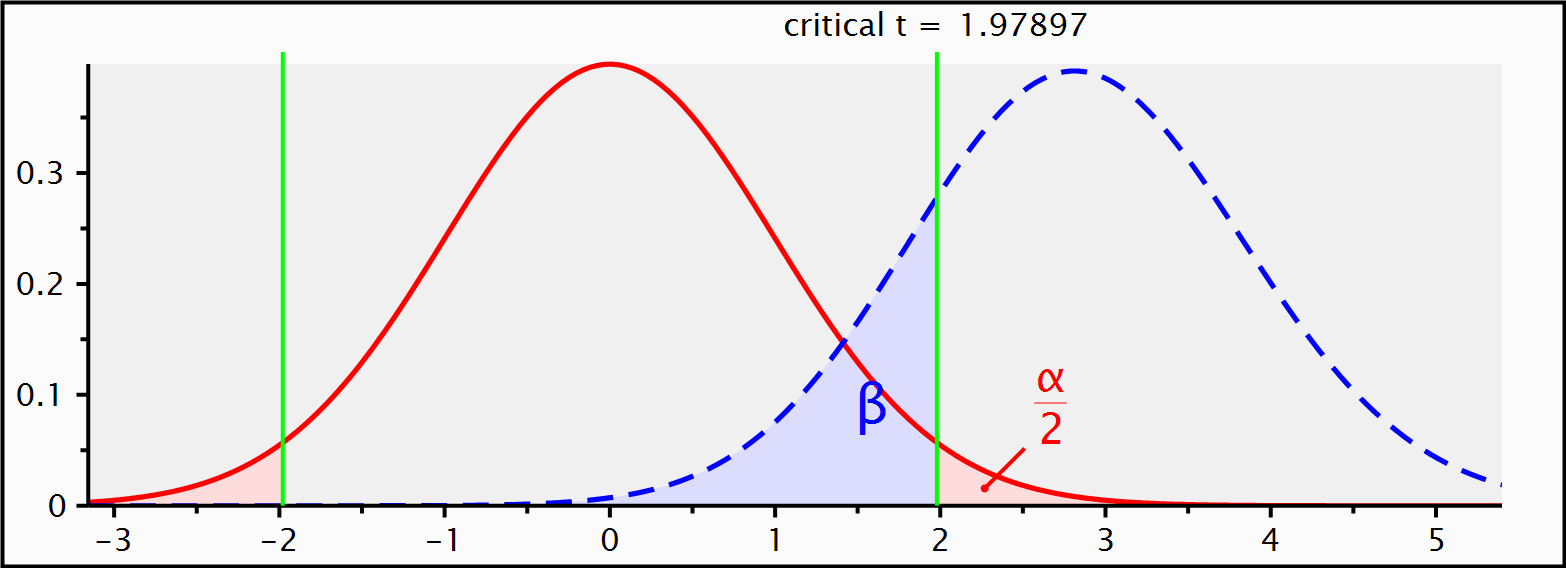
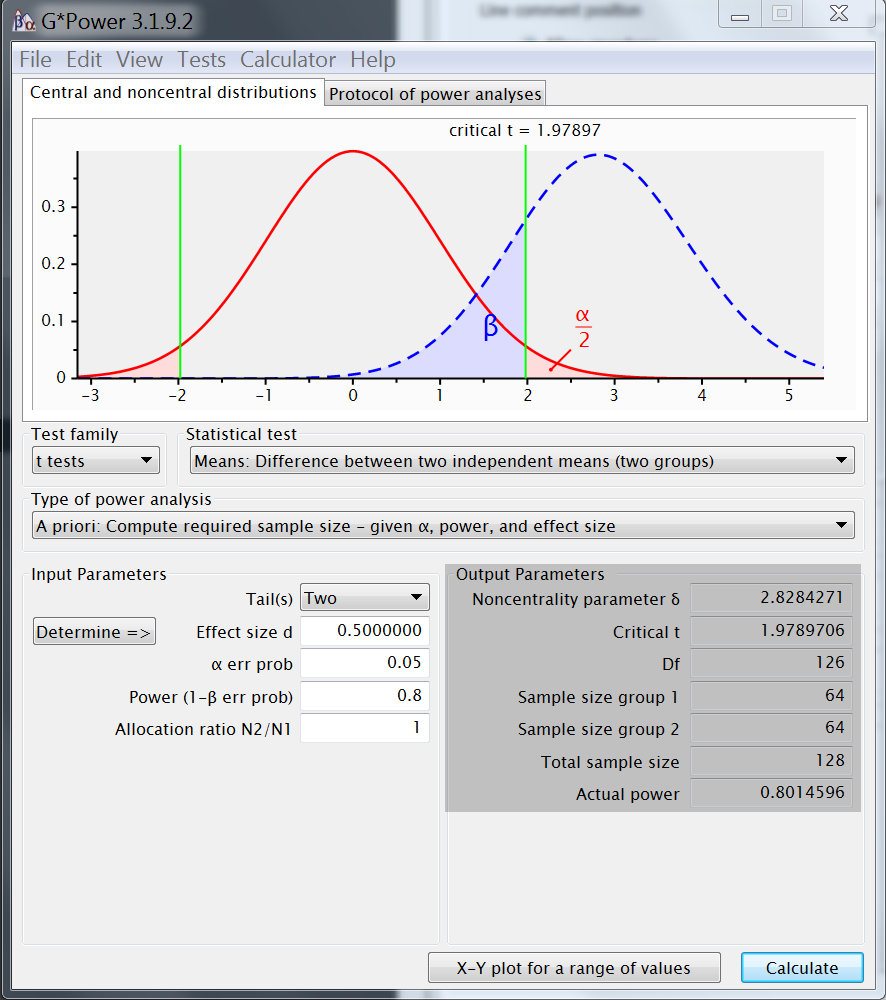
GPower output
~ reference example output- sample size (n) = 64 x 2 = (
128) - degrees of freedom (df) = 126 (128-2)
- critical t = 1.979
- decision boundary given α and df
qt(.975,126)
- decision boundary given α and df
- non centrality parameter ( δ ) = 2.8284
- shift
Ha(true) away fromHo(null)
2/(4*sqrt(2))*sqrt(64)
- shift
- distributions: central + non-central
- power ≥ .80 (1- β) = 0.8015
- sample size (n) = 64 x 2 = (
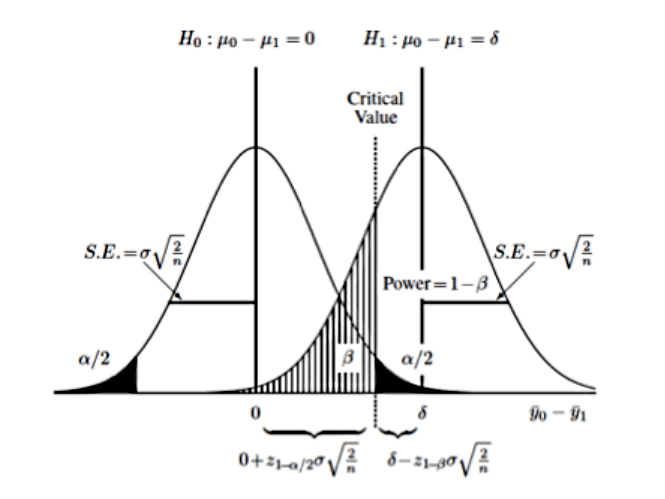
Non-centrality parameter ( δ ), shift Ha from Ho
Hoacts as benchmark → eg., no difference- set cutoff on
Ho ~ t(ncp=0,df)using α, - reject
Hoif test returnsimplausiblevalue
- set cutoff on
Haacts as truth → eg., difference of .5 SDHa ~ t(ncp!=0,df)- δ as violation of
Ho→ shift (location/shape)
δ, the non-centrality parameter
- combines
- assumed
effect size(target or signal) - conditional on
sample size(information)
- assumed
- determines overlap (power ↔ sample size)
- probability beyond cutoff at
Hoevaluated onHa
- probability beyond cutoff at
- combines
Alternative: divide by N
- Constant difference, changing shape
- divide by n: sample size ~ standard deviation
- non-centrality parameter: sample size ~ location
n=(Zα/2+Zβ)2∗2∗σ2d2
n=(−1.96−0.84)2∗2∗4222
n=62.79
Type I/II error probability
Inference test based on cut-off's (density → AUC=1)
Type I error: incorrectly reject
Ho(false positive):- cut-off at
Ho, error prob. α controlled - one/two tailed → one/both sides informative ?
- cut-off at
Type II error: incorrectly fail to reject
Ho(false negative):- cut-off at
Ho, error prob. β obtained fromHa Haassumed known in a power analyses
- cut-off at
power = 1 - β = probability correct rejection (true positive)
Inference versus truth
- infer: effect exists vs. unsure
- truth: effect exist vs. does not
| infer=Ha | infer=Ho | sum | |
| truth=Ho | `α` | 1- `α` | 1 |
| truth=Ha | 1- `β` | `β` | 1 |
Create plot
- create plot
- X-Y plot for range of values
- Y-axis / X-axis / curves and constant
- assumes calculated analysis
~ reference example
- beware of order !
- plot sample size (y-axis)
- by type I error α (x-axis)
- from .01 to .2 in steps of .01
- for 4 values of power (curves)
- with values .8 in steps of .05
- and assume an effect size (constant)
- .5 from the reference example
- notice Table option
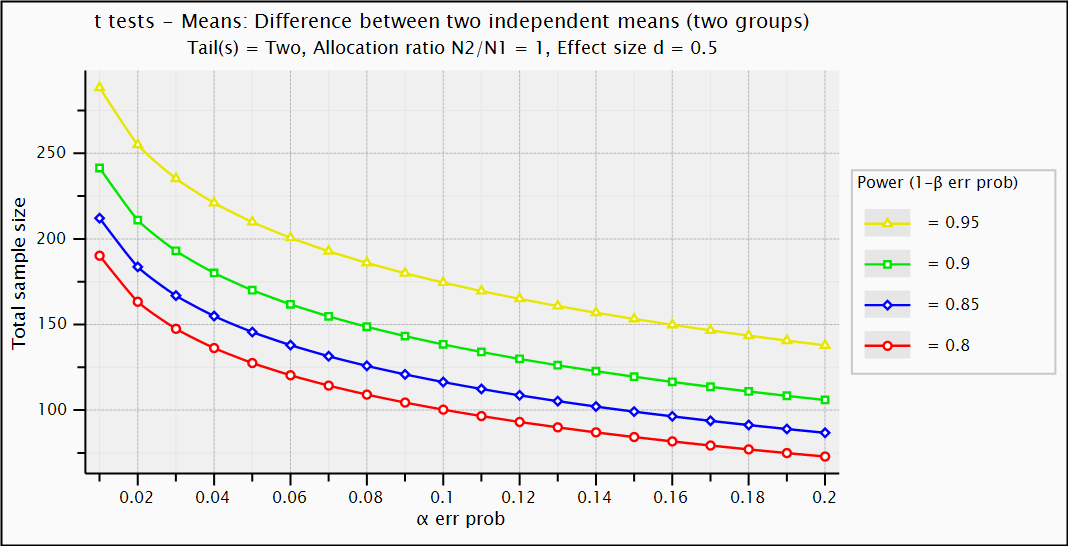
Exercise on errors, interpret plot
- Understand the building blocks, interpret the plot
- where on the red curve (right)
type II error = 4 * type I error ? - when smaller effect size (.25), what changes ?
- plot power instead of sample size
- with 4 power curves
with sample sizes 32 in step of 32 - what is relation type I and II error ?
- with 4 power curves
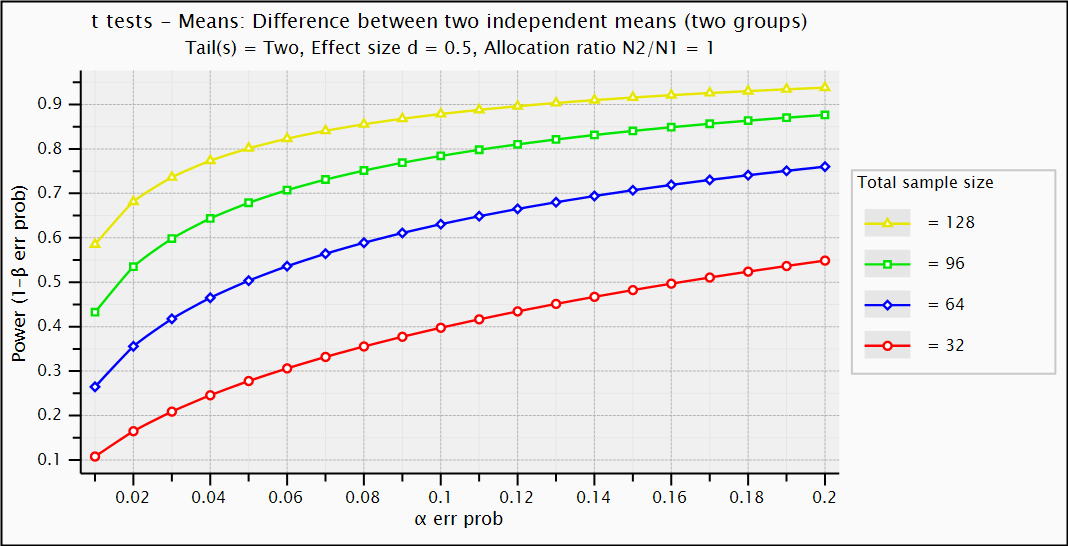
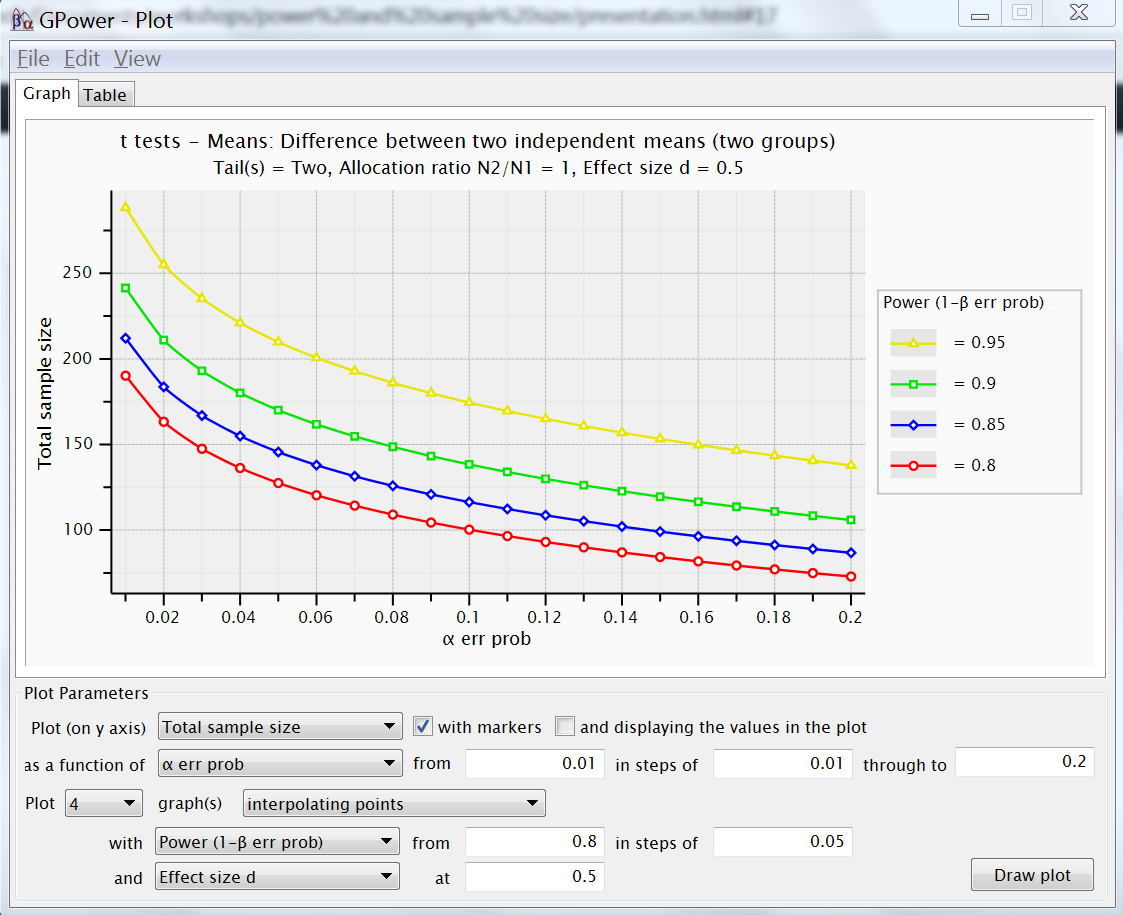
- what would be difference between curves for α = 0 ?
Decide Type I/II error probability
Popular choices
- α often in range .01 - .05 → 1/100 - 1/20
- β often in range .2 to .1 → power = 80% to 90%
α & β inversely related
- power = 1 - β > 1 - 2 * α
- α & β often selected in 1/4 ratio
type I error is 4 times worse !! - which error you want to avoid most ?
- cheap aids test ? → avoid type II
- heavy cancer treatment ? → avoid type I
- probability for errors always exists
Effect sizes, in literature
- Cohen, J. (1992). A power primer. Psychological Bulletin, 112, 155–159.
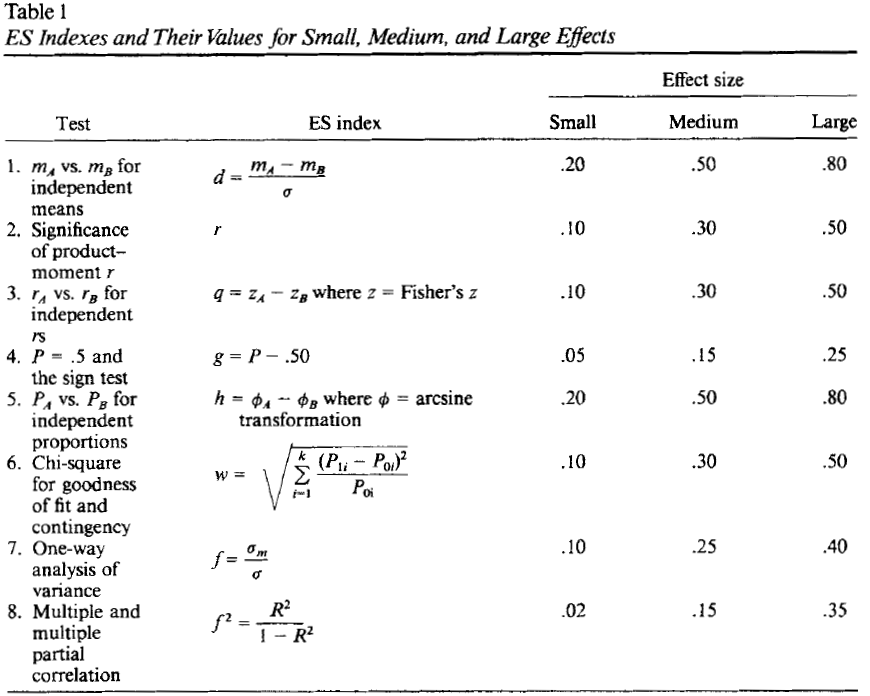
- Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed).
- famous Cohen conventions but beware, just rules of thumb
- more than 70 different effect sizes... most of them related
- Ellis, P. D. (2010). The essential guide to effect sizes: statistical power, meta-analysis, and the interpretation of research results.

Effect sizes, in GPower (Determine)
Effect sizes are test specific
- t-test → group means and sd's
- one-way anova →
variance explained & error - regression →
sd's and correlations - . . . .
GPower helps with
Determine- sliding window
- one or more effect size specifications
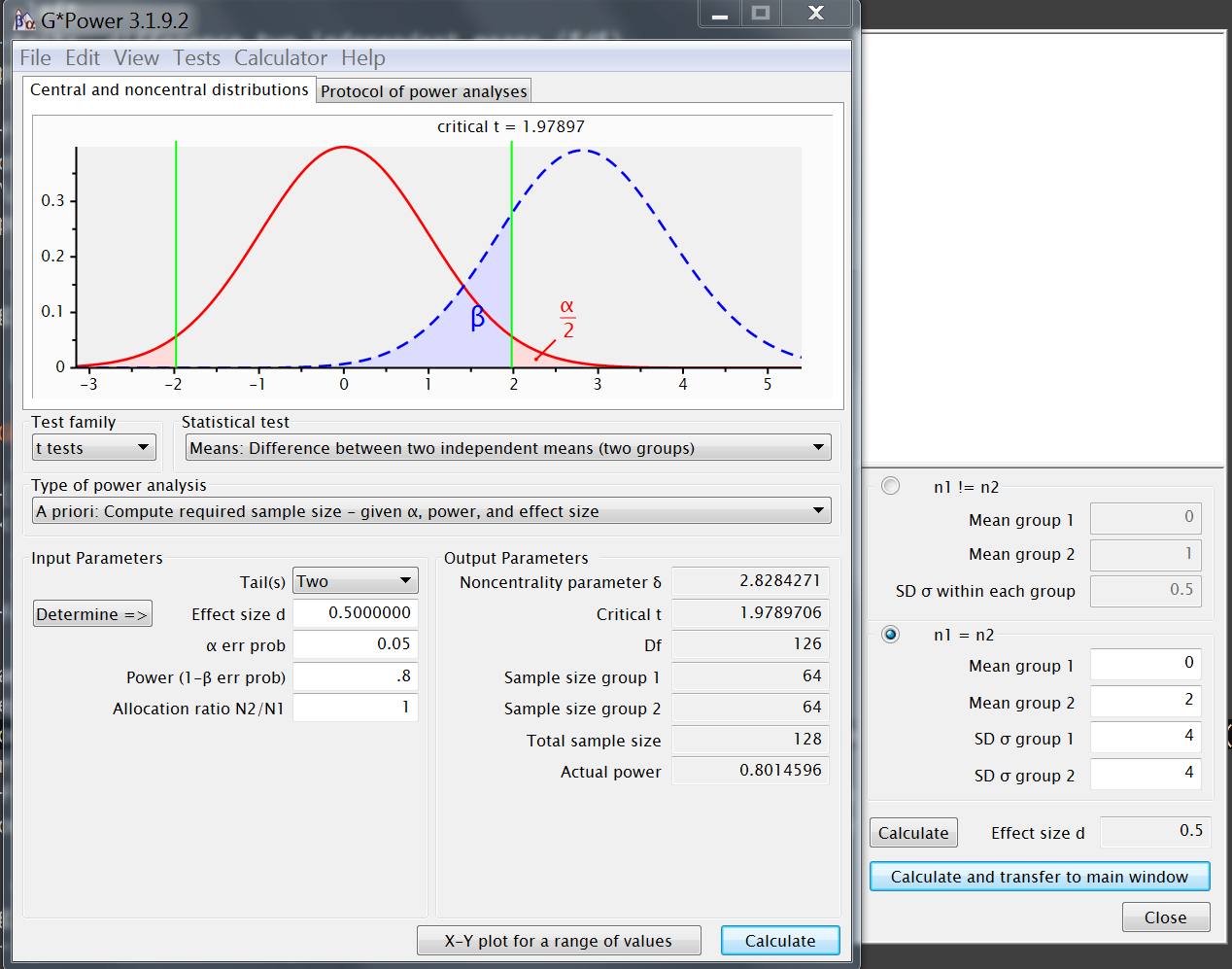
Exercise on effect sizes, ingredients Cohen's d
- For the
reference example:- change mean values from 0 and 2 to 4 and 6, what changes ?
- change sd values to 2 for each, what changes ?
- effect size ?
- total sample size ?
- critical t ?
- non-centrality ?
- change sd values to 8 for each, what changes ?
- change sd to 2 and 5.3, or 1 and 5.5,
how does it compare to 4 and 4 ?
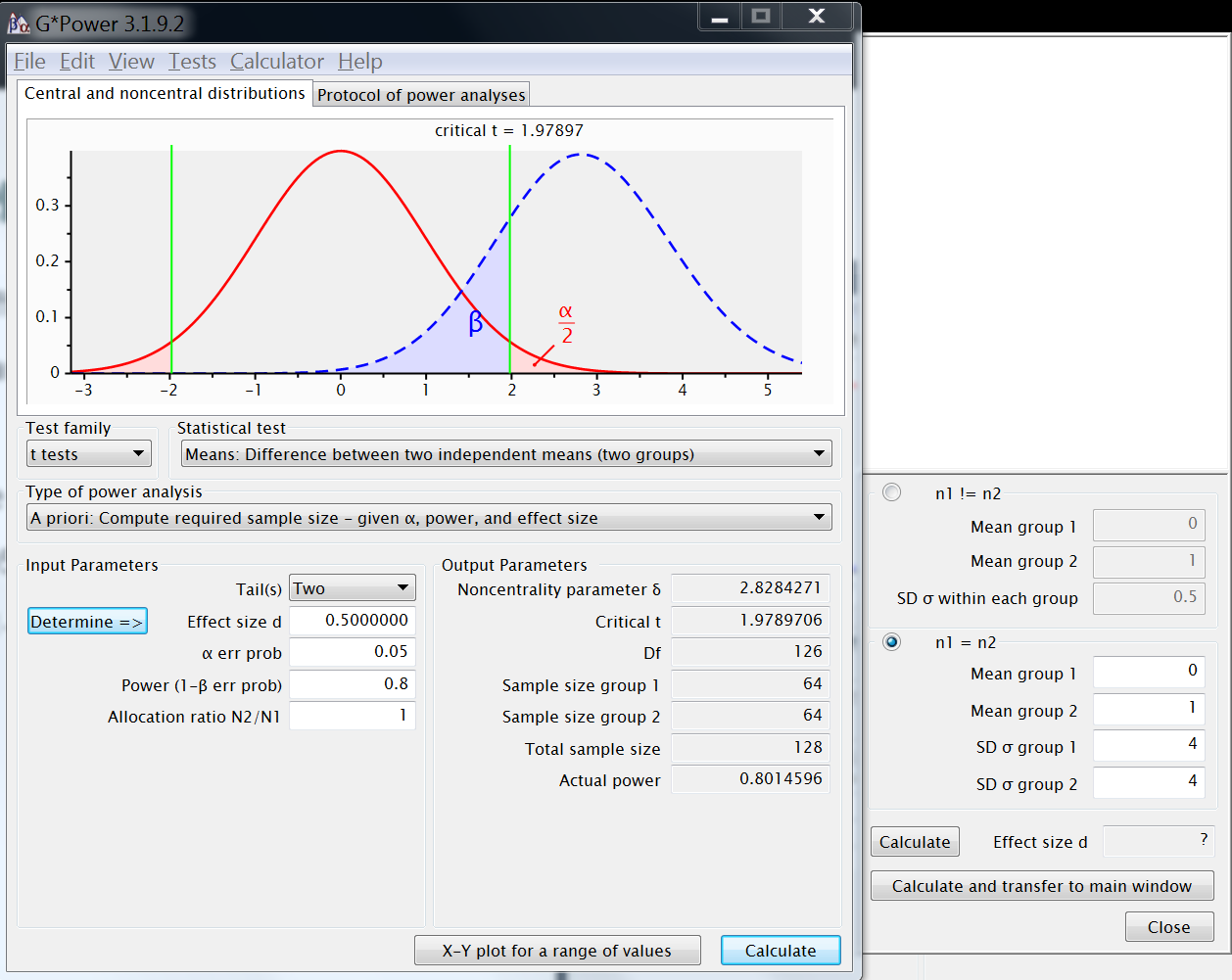
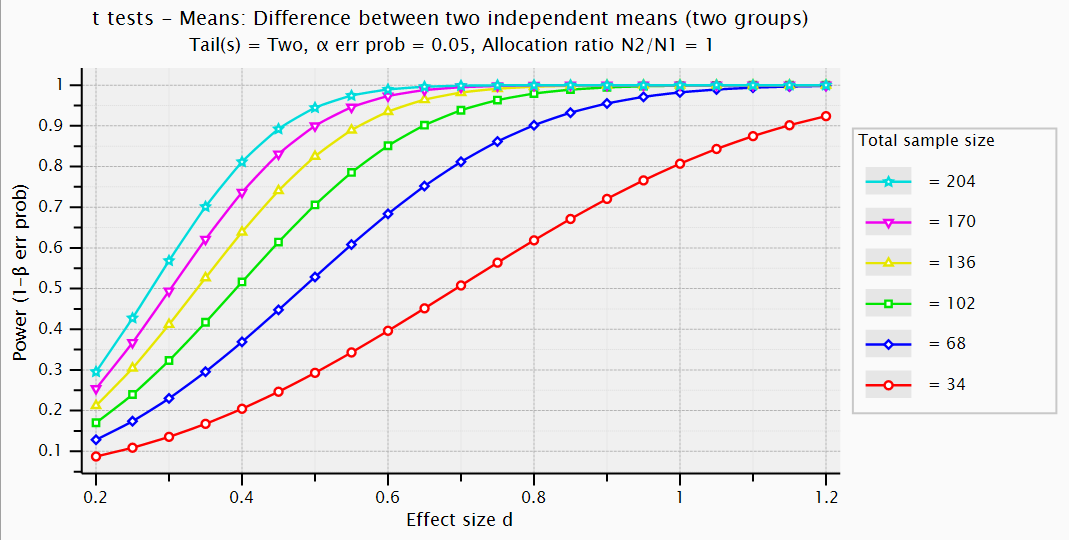
Exercise on effect sizes, plot
- For the
reference example:- plot powercurve: power by effect size
- compare 6 sample sizes: 34 in steps of 34
- for a range of effect sizes in between .2 and 1.2
- use α equal to .05
- pinpoint the situations from previous section on the plot (sd=4 and 2).
- how does power change when doubling the effect size ?
- powercurve → X-Y plot for range of values
Exercise on effect size, imbalance
For the
reference example:- compare for allocation ratios 1, .5, 2, 10, 50
- repeat for effect size 1, and compare
? no idea why n1 ≠ n2
after calculate plot, to change allocation ratio
Relation sample & effect size, type I & II errors
Building blocks:
- sample size ( n )
- effect size ( Δ )
- alpha ( α )
- power ( 1−β )
each parameter
conditional on others
- GPower → type of power analysis
- Apriori: n
~α,power, Δ - Post Hoc:
power~α, n, Δ - Compromise:
power, α~β/α, Δ, n - Criterion: α
~power, Δ, n - Sensitivity: Δ
~α,power, n
- Apriori: n
Getting your hands dirty
# calculatorm1=0;m2=2;s1=4;s2=4alpha=.025;N=128var=.5*s1^2+.5*s2^2d=abs(m1-m2)/sqrt(2*var)*sqrt(N/2)tc=tinv(1-alpha,N-1)power=1-nctcdf(tc,N-1,d)
- in
R- qt → get quantile on
Ho( Z1−α/2 ) - pt → get probability on
Ha(non-central)
- qt → get quantile on
.n <- 64.df <- 2*.n-2.ncp <- 2 / (4 * sqrt(2)) * sqrt(.n).power <- 1 - pt( qt(.975,df=.df), df=.df, ncp=.ncp ) - pt( qt(.025,df=.df), df=.df, ncp=.ncp)round(.power,4)## [1] 0.8015A variance ratio perspective on multiple groups
Multiple groups → not one effect size
dF-test statistic & effect size
f, ratio of variances σ2between/σ2withinσ2between = variance between groups differences
σ2within = variance within group differences
Example: one control and two treatments
reference example+ 1 group- sd within each group, for all groups (C,T1,T2) = 4
- means C=0, T1=2 and for example T2=4
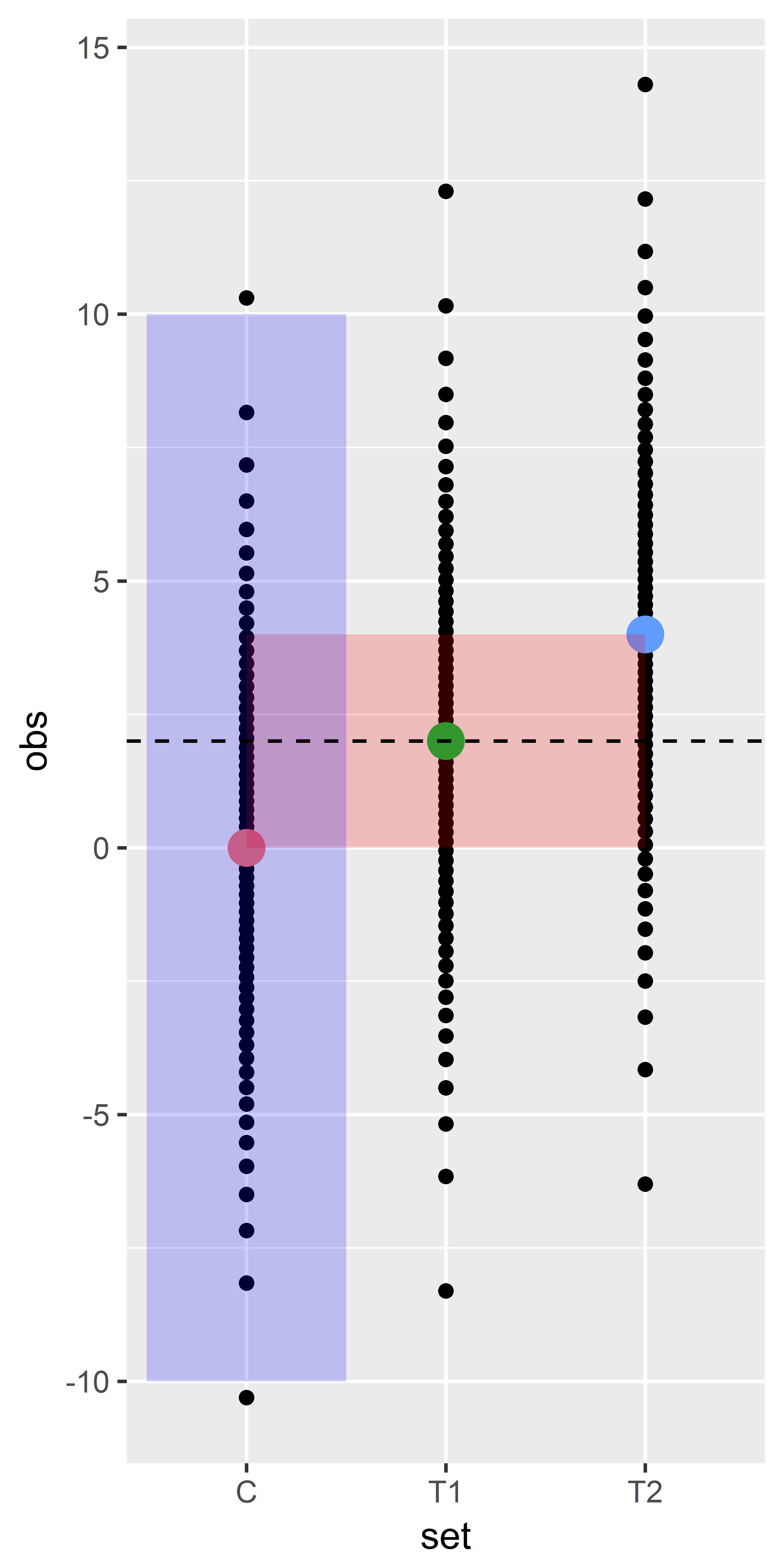
Exercise proportions
- GPower: Fisher Exact Test (exact / proportions, difference 2 independent proportions)
For odds ratio = 2, with p2 reference probability .6
Plot power over proportions .5 to 1
Include 5 curves, sample sizes 328, 428, 528...
With type I error .05
Explain curve minimum, relation sample size ?
Repeat for one-tailed, difference ?
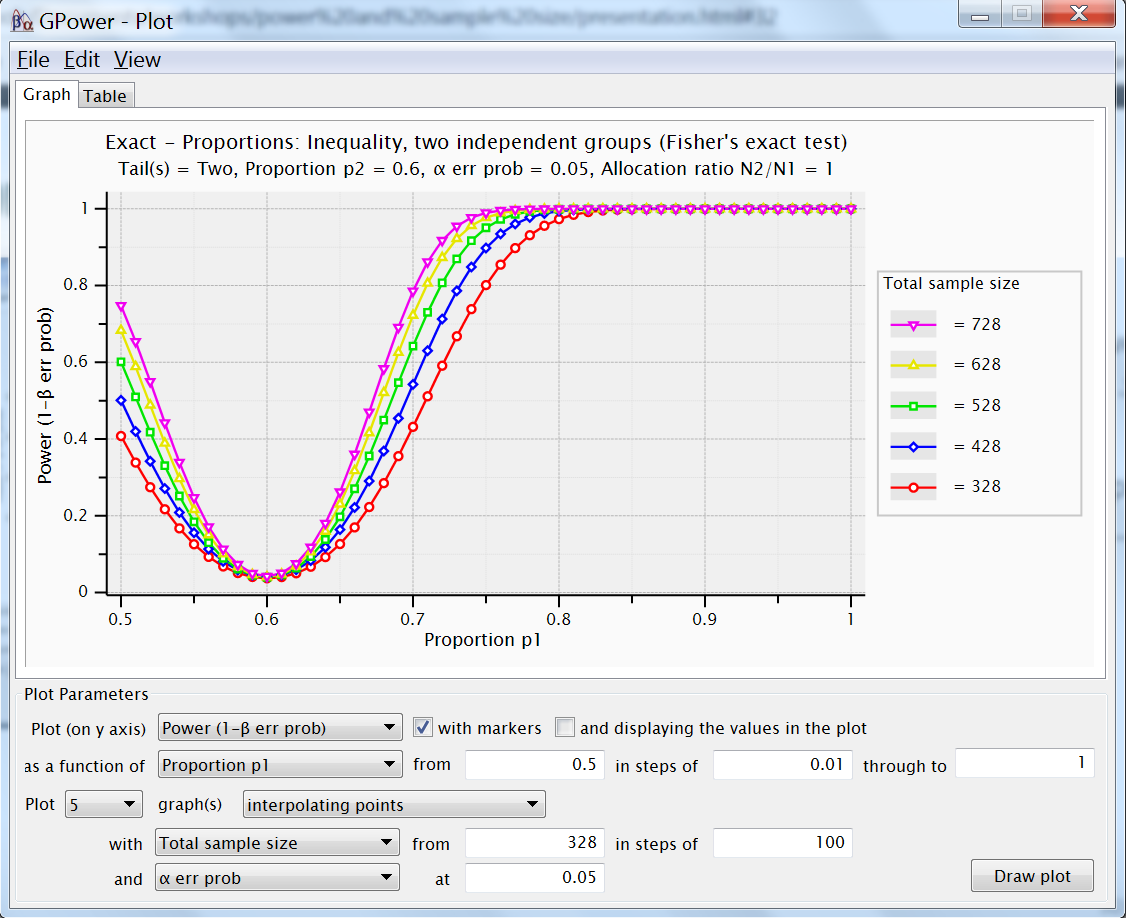
Solution for proportions
- GPower: Fisher Exact Test (exact / proportions, difference 2 independent proportions)
- For odds ratio = 2, with p2 reference probability .6
- Plot power over proportions .5 to 1
- Include 5 curves, sample sizes 328, 428, 528...
- With type I error .05
- Explain curve minimum, relation sample size ?
- power for proportion compared to reference .6
- minimum is type I error probability
- sample size determines impact
- Repeat for one-tailed, difference ?
- one-tailed, increases power (both sides !?)